
Autonomous AI Agent Collectives: A Four-Layer Architecture
When one model isn't enough: architecting SLM networks that learn from each other.

How do you build AI systems where hundreds of agents coordinate in messy, physical environments, with unreliable networks and limited power - without a single central coordinator in the cloud?
Let many small agents think locally, then let them communicate peer-to-peer and share memory in a way that degrades gracefully when the network misbehaves.
This is the promise of autonomous AI collectives: networks of small, specialized models at the edge that share state and coordinate behavior. No monolithic model trying to understand everything. No single orchestrator or cloud API call in the hot path of every decision. Just peers collaborating at the edge, with the cloud handling training, governance, and heavy computation in the background.
Why This Architecture Matters Now
Three trends are converging to make distributed edge intelligence not just interesting, but increasingly necessary.
The Autonomy Problem. Connectivity is never guaranteed. Mobile devices move through dead zones, elevators, and subway tunnels. IoT sensors deployed across sprawling campuses, delivery fleets navigating dense urban areas, or warehouse sensors spread across multiple facilities often have only intermittent or metered connectivity. The architecture must assume the connection might not be there - and keep working anyway.
The Bandwidth Problem. We’re drowning in data. A single autonomous vehicle can generate terabytes of raw sensor logs per day. Shipping every raw frame in real time is rarely economical; radio spectrum and backhaul capacity are finite, and most of that data will be discarded or heavily compressed upstream anyway. Edge collectives invert the default: process richly on the device, share insights and aggregates (vectors, summaries, anomalies), and offload raw logs selectively when they’re genuinely useful.
The Resilience Problem. Cloud outages, flaky last-mile networks, and local failures are unavoidable. Malicious actors exist. Regulations increasingly require graceful degradation and safety even when “the internet is down.” Systems that depend on a central coordinator collapse when that coordinator becomes unreachable.
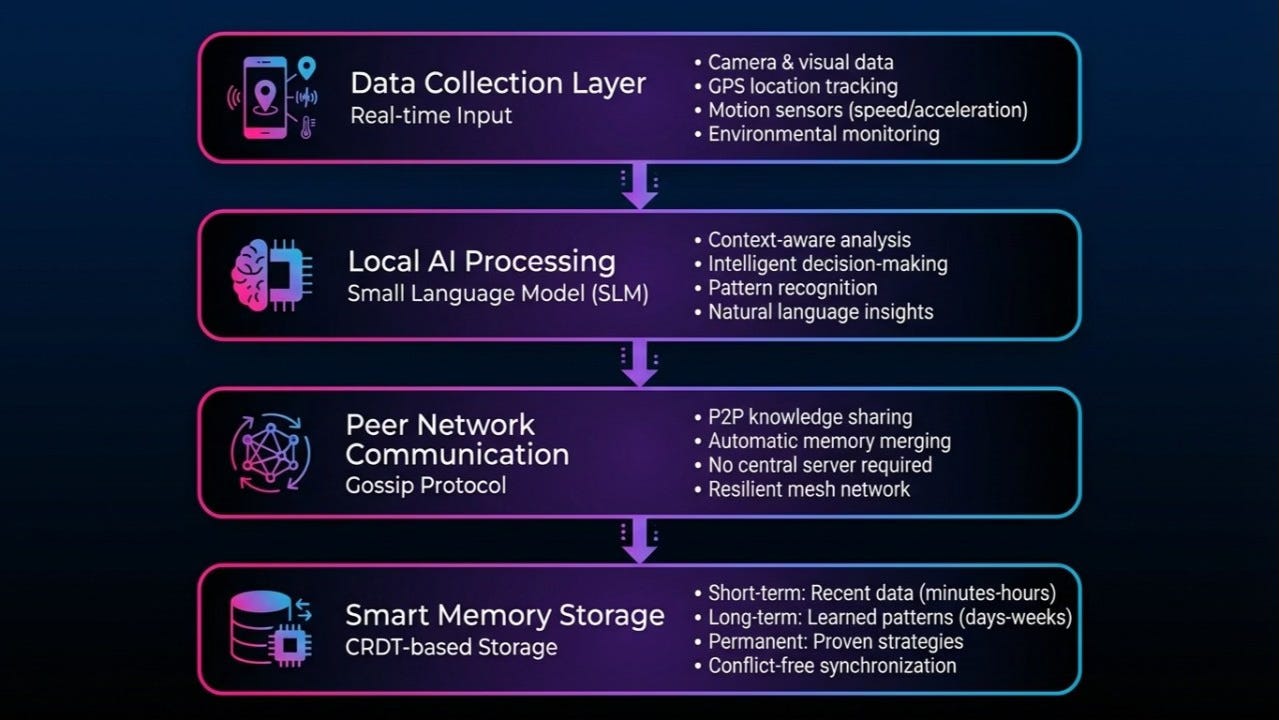
The architecture that addresses these constraints is a four-layer stack:
Sensing the world
Local AI processing with Small Language Models (SLMs)
Peer-to-peer communication
Shared memory
Here’s how they fit together, and where the real engineering trade-offs show up.
Layer 1: Sensing the World
Everything starts with data. Edge devices are increasingly saturated with sensors: cameras, microphones, accelerometers, magnetometers, depth sensors, environmental sensors for temperature, humidity, and air quality, and more.
Your smartphone is a perfect example: it continuously collects accelerometer and gyroscope signals to detect orientation, GPS for location, proximity to know when it’s near your face, and ambient light to adjust brightness. A similar pattern applies to warehouse robots, smart meters, or industrial equipment.
The catch is energy. Constantly streaming high-fidelity sensor data is a battery killer and a bandwidth hog. If every sensor is “always on” at full resolution, nothing that runs on a battery will last long, and nothing that shares a radio channel will stay uncongested.
The architectural trick is cascaded wake-up: ultra-low-power sensors (simple accelerometers, binary switches, cheap PIR motion sensors) run continuously. These act as triggers for more expensive sensors (high-resolution cameras, radar, depth sensors). Those more expensive sensors then trigger local AI processing, which decides whether anything interesting is happening. The system treats high-bandwidth sensing as a precious resource, not a default.
We shouldn’t pretend sensors are perfect. In real deployments, most of the pain comes from sensor calibration drifting over time, devices mounted incorrectly or moved without updating the configuration, and cheap hardware failing silently and spewing garbage. Cascaded wake-up doesn’t fix any of that on its own; it just ensures you don’t waste energy and bandwidth amplifying insufficient data. You still need calibration routines, health checks, and sanity checks on the sensors’ reports.
The key insight of Layer 1: most raw sensor data doesn’t deserve to leave the device. We process it locally first, extract the bits that matter, and only then consider sharing.
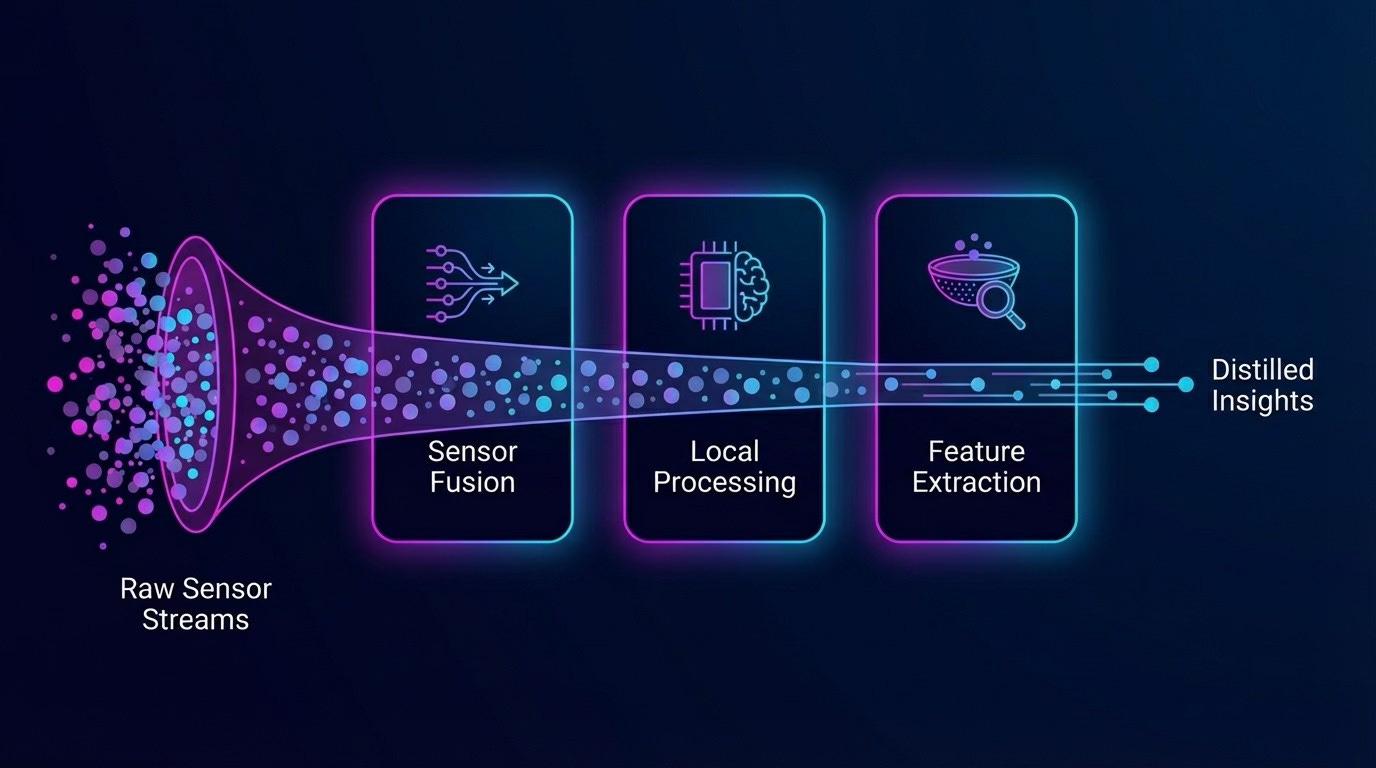
Layer 2: Local AI Processing with Small Language Models
This is where things get interesting.
Small Language Models (SLMs) are compact neural models that can run on smartphones, single-board computers, and embedded devices with dedicated AI accelerators. They don’t match frontier LLMs in raw capability, but they more than suffice for many edge tasks - especially when they are specialized.
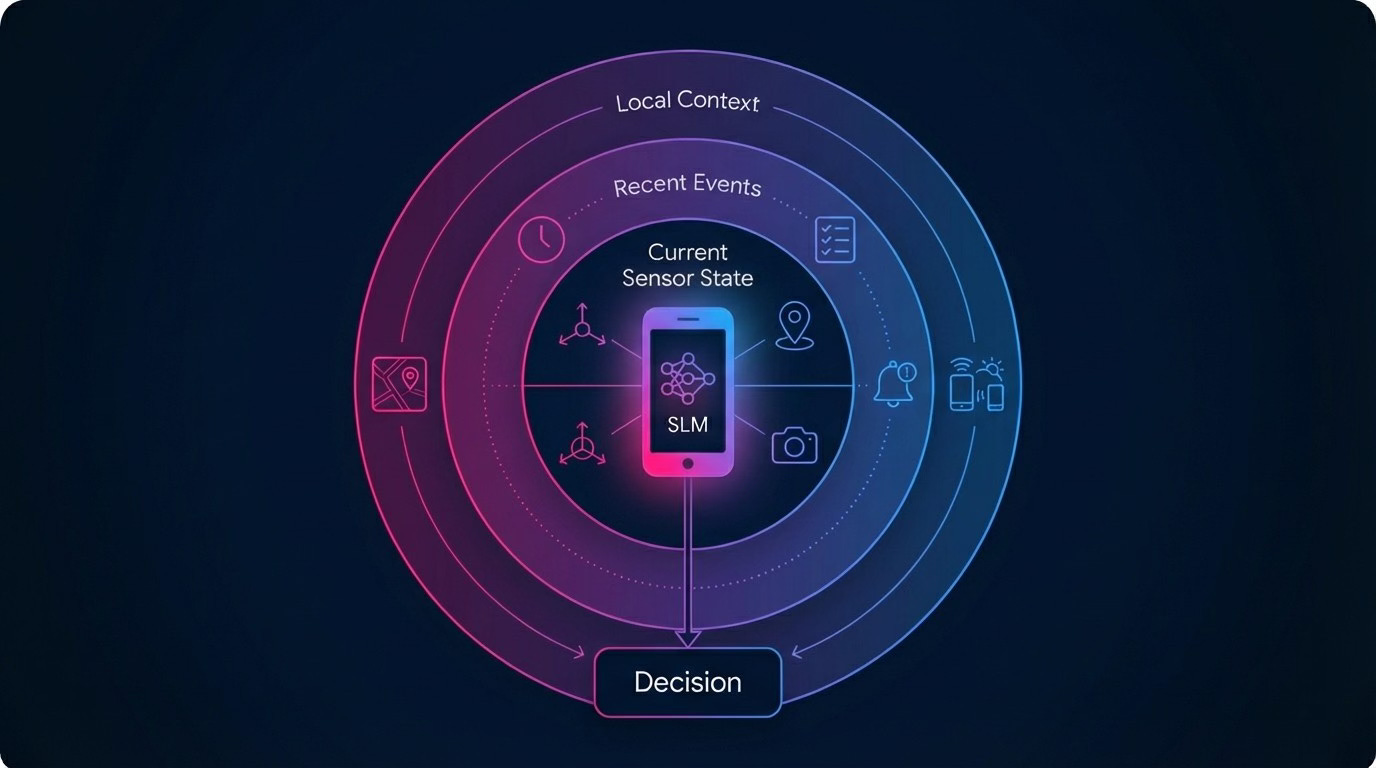
An SLM on a robot, drone, smartphone, or sensor hub is responsible for understanding local context (sensor readings, recent events, local map), making task-level decisions (”inspect that pallet”, “ping the human operator”, “re-route around obstacle”), and compressing observations into useful summaries to share with other agents.
“Small” doesn’t mean “limited” - provided you respect the hardware constraints. You quantize aggressively to reduce model size and memory footprint. You keep context windows short and focused on the task at hand. You offload anything that’s not latency-critical to idle moments or the cloud. A warehouse robot doesn’t need to write poetry. It needs to interpret a small local state, follow safety rules, and decide among a finite set of actions.
Just as important as specialization is constraining what the model is allowed to do. On the edge, you don’t want a free-form agent with arbitrary side effects. You want fixed action schemas (”move to X”, “scan barcode Y”, “send alert Z”), clearly defined data access (”you may read these sensors and these configuration values”), and explicit handoff rules (”if in doubt, ask a human or escalate to a central service”). The SLM is wrapped in policies and structured interfaces so it can’t improvise its own notion of “safe” or “allowed”.
SLMs are typically pretrained and fine-tuned in the cloud, then distilled or adapted to run efficiently on target hardware and deployed via OTA updates in staged rollouts. However, on-device learning is increasingly viable - lightweight fine-tuning, federated learning, and local adaptation let models improve from local data without shipping raw observations upstream. The edge model handles runtime decisions; the cloud model (or models) are the teachers and auditors, but the boundary is becoming more fluid.
Layer 3: Peer-to-Peer Communication
This is the layer that makes the whole system collective instead of just “lots of isolated smart devices.”
Traditional architectures assume a hub-and-spoke model: all agents talk to a cloud or central broker. That works until connectivity is intermittent, latency budgets are tight, or the number of agents grows into the thousands. At that point, centralized coordination becomes a bottleneck and a single point of failure.
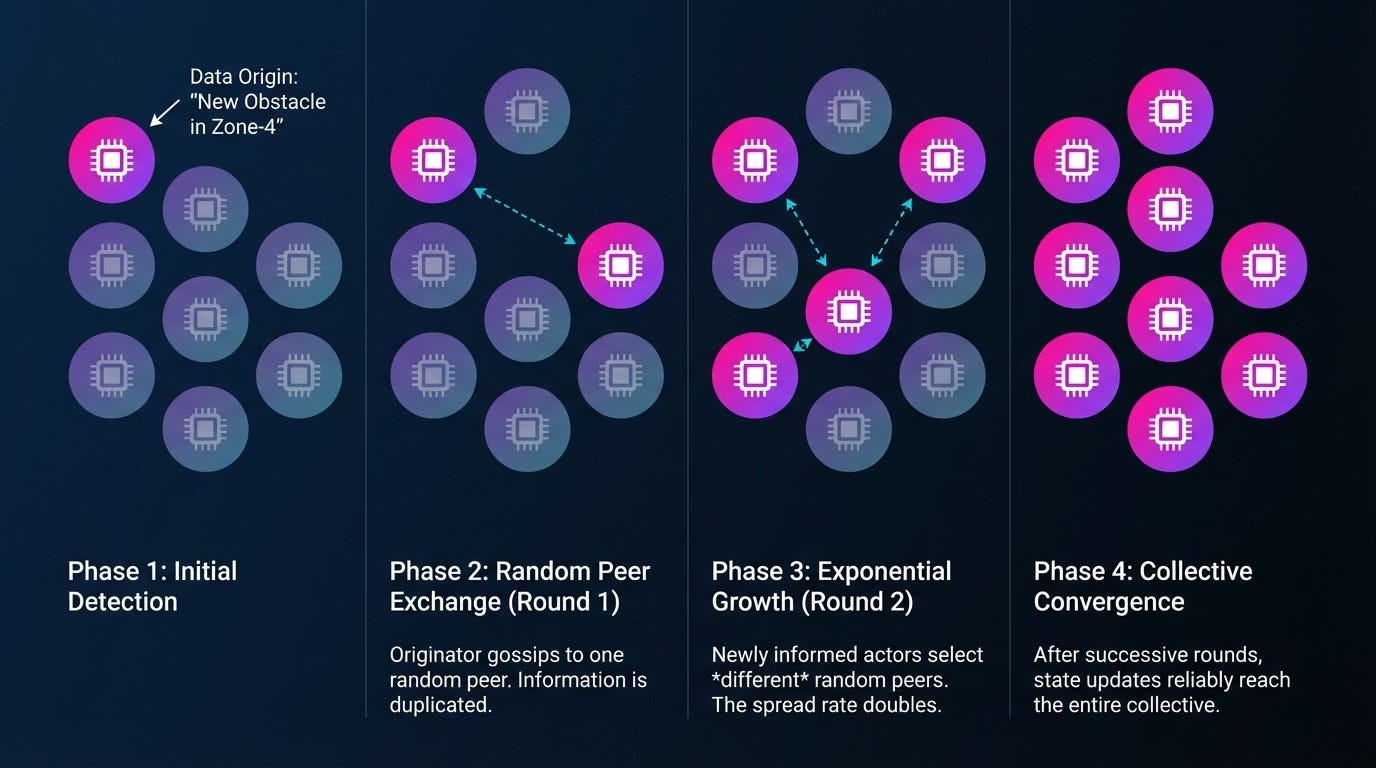
Gossip protocols - borrowed from distributed databases - are a better fit. Each node periodically exchanges state with a small random subset of peers. Information spreads epidemically through the network. There is no single authoritative node, just eventual convergence.
To make this viable at the edge, agents use semantic compression. Instead of streaming raw sensor data, they share summaries: “Aisle 7 blocked near coordinates (x, y)”, “Battery level critical, looking for charging dock”, “New obstacle in Zone-4”. These summaries are often vectors, hashes, or small structured messages - not video feeds
Trust and Robustness
Real-world networks are noisy, and nodes can be buggy or malicious. Two mechanisms help: cryptographic signatures (each agent signs the updates it originates, so receivers can verify who claimed what) and heuristics like webs of trust and outlier detection (agents track how often peers have been “right” in the past, and down-weight reports that conflict with the majority or come from low-trust nodes).
These mechanisms significantly improve robustness, but they do not provide formal Byzantine Fault Tolerance in the strong, protocol-level sense. A correctly authenticated but compromised robot can still spam bad data; a swarm of Sybil nodes can still collude. Signatures help with identity. Gossip-level heuristics help with plausibility. Together, they mitigate many Byzantine-style issues in practice, but they’re not a mathematical cure-all.
When Eventual Agreement Isn’t Enough
Sometimes you need certain decisions to be globally consistent: “This pallet ID is assigned to exactly one robot”, “This firmware version is the current valid version”, “This log of safety incidents is in a single, agreed-upon order.”
For those cases, systems often use consensus algorithms like RAFT. A small cluster elects a leader, the leader proposes log entries, followers replicate the log, and an entry is considered committed when a majority have written it. This gives strong consistency - but at a cost: more messages per decision, sensitivity to network instability, and need for a relatively well-connected control plane.
The engineering art is deciding which decisions must never diverge, and paying the coordination cost only there. In practice, large systems use gossip for “soft state” and hints (”Aisle 7 is probably blocked”, “This robot has high battery and is nearby”) and consensus for “hard state” where divergence is unacceptable (”Here is the canonical task assignment log”, “Here is the authoritative configuration for this device class”).
Layer 4: Smart Memory with CRDTs
Here’s where many edge-AI architectures quietly fall apart: memory.
An AI that forgets everything between sessions is useless. But naive shared memory - “just write everything into a central database” - assumes reliable connectivity and often a single authoritative writer. That’s exactly what edge environments lack.
We want a memory system that works with intermittent connectivity, lets agents independently update their view of the world, converges when nodes reconnect, and doesn’t require a single master while still behaving predictably.
This is where CRDTs (Conflict-free Replicated Data Types) come in. CRDTs are data structures designed to be replicated across many nodes. Each replica can be updated locally without locking or coordination. When replicas sync, they merge in a mathematically defined way that guarantees convergence, regardless of message ordering or duplication. If you model shared knowledge as CRDTs, then temporary network partitions or independent updates are expected, not exceptional.
What CRDTs Do - and Don’t Do
It’s crucial to be clear: CRDTs resolve syntactic conflicts (which operations apply in which order) by defining a merge rule that always produces a single, well-defined state. They do not decide semantic correctness - whether that merged state actually matches reality or is safe.
If two robots concurrently write “aisle 7 is blocked” and “aisle 7 is clear” into a last-writer-wins register, the CRDT will pick one based on timestamps or version vectors. It has no idea which one is true. Semantic reconciliation still requires application logic, context (”which robot was physically there more recently?”), and possibly human oversight for high-risk cases.
CRDTs also assume a mostly benign environment: nodes eventually exchange updates, replicas apply the CRDT logic correctly, and most nodes are not actively malicious. They do not by themselves protect against bugs, clock misconfiguration, or adversarial updates.
The CRDT Toolbox
Different types of shared state call for different CRDT structures. Four types show up repeatedly in swarm architectures:
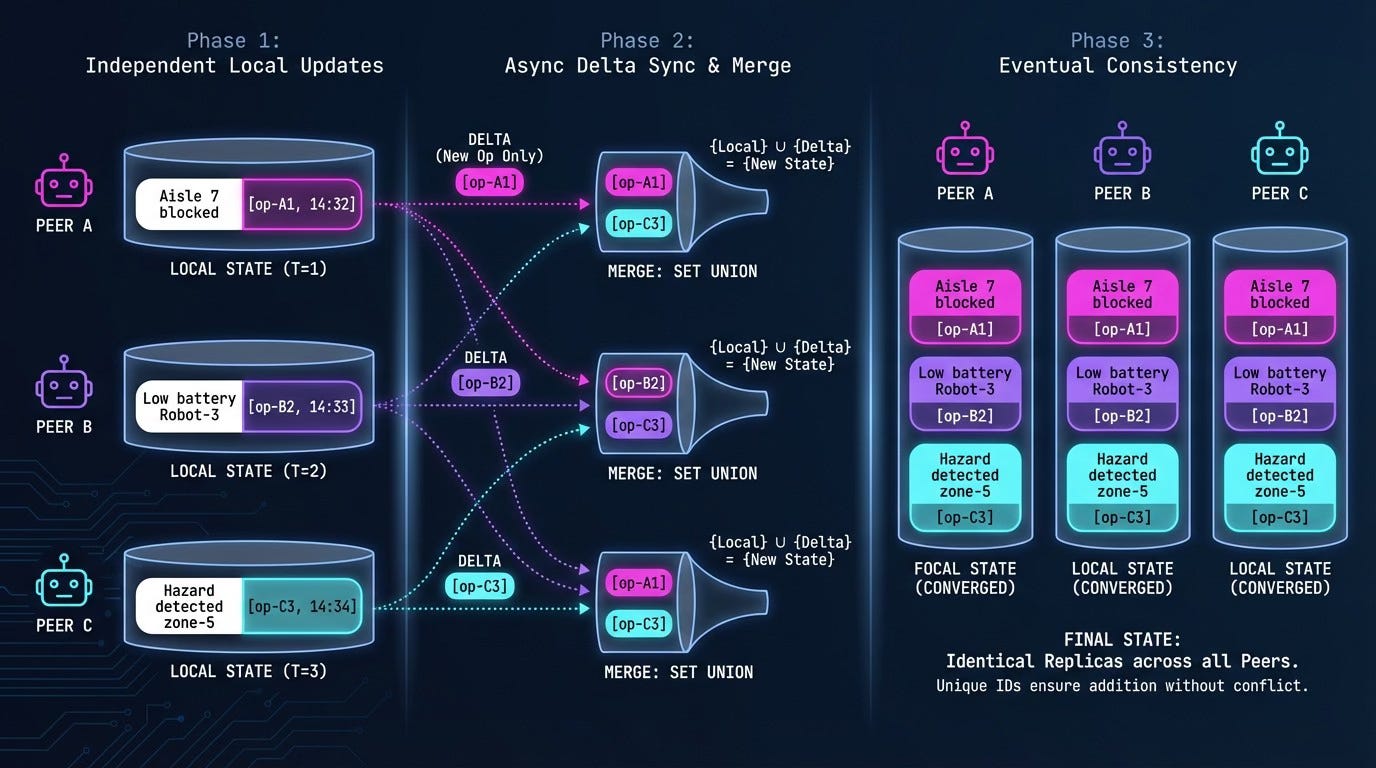
G-Counters (Grow-only Counters) track events across the swarm: items scanned, alerts raised, tasks completed. Each node keeps its own counter component; the global value is the element-wise max over all components.
LWW-Registers (Last-Writer-Wins Registers) store the freshest value for a given key: “current temperature reading at sensor X”, “current status of robot Y”. Each write carries a timestamp; when merging, the register keeps the value with the latest timestamp. Best used for state where occasional overwrites are acceptable.
OR-Sets (Observed-Remove Sets) handle shared collections like “active alerts in the warehouse”, “devices currently online”, or “known obstacles in the map”. They let agents add and remove entries concurrently while still converging to the same final set.
LWW-Maps hold structured configurations and preferences: per-device parameters, learned heuristics (”avoid this route during shift change”), policy flags toggled over time. Each key in the map behaves like its own little LWW register.
One implementation detail worth noting: delta-state CRDTs can dramatically reduce bandwidth by sending only changes rather than full state - critical on constrained links
Memory Tiers
A well-designed agent collective organizes shared state into tiers to manage the “noise vs. signal” ratio.
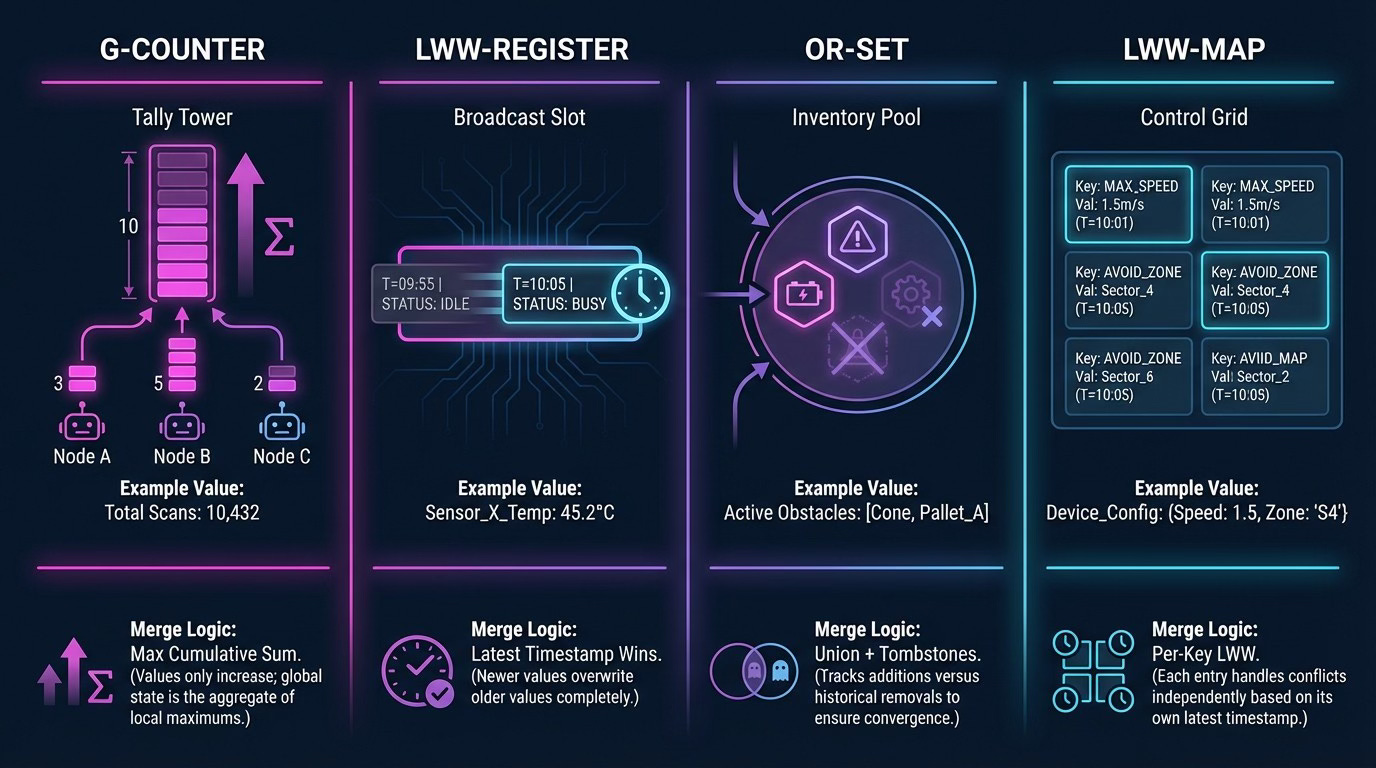
Short-term memory (minutes to hours) holds recent sensor readings, ephemeral alerts, and transient task state. High churn; often stored in LWW-registers and small ring buffers on each device. Safe to forget or aggregate aggressively.
Long-term memory (days to weeks) holds patterns extracted from short-term data: “pallet arrivals spike on Mondays”, “aisle 5 is frequently blocked between 14:00–16:00”. Often aggregated counters, time-series models, or compact embeddings computed from short-term signals. Shared across the swarm as CRDTs so multiple agents can contribute observations.
Permanent memory (indefinite) holds strategies that consistently work (”never route forklifts within 2m of this safety zone”), safety policies, and carefully curated knowledge. Updated infrequently, often with explicit review or governance. Replicated more cautiously, sometimes with stronger consistency guarantees.
Think of permanent memory as the constitution of the swarm; long-term memory as its shared intuition; short-term memory as its working memory.
The Layers in Action: A Warehouse Scenario
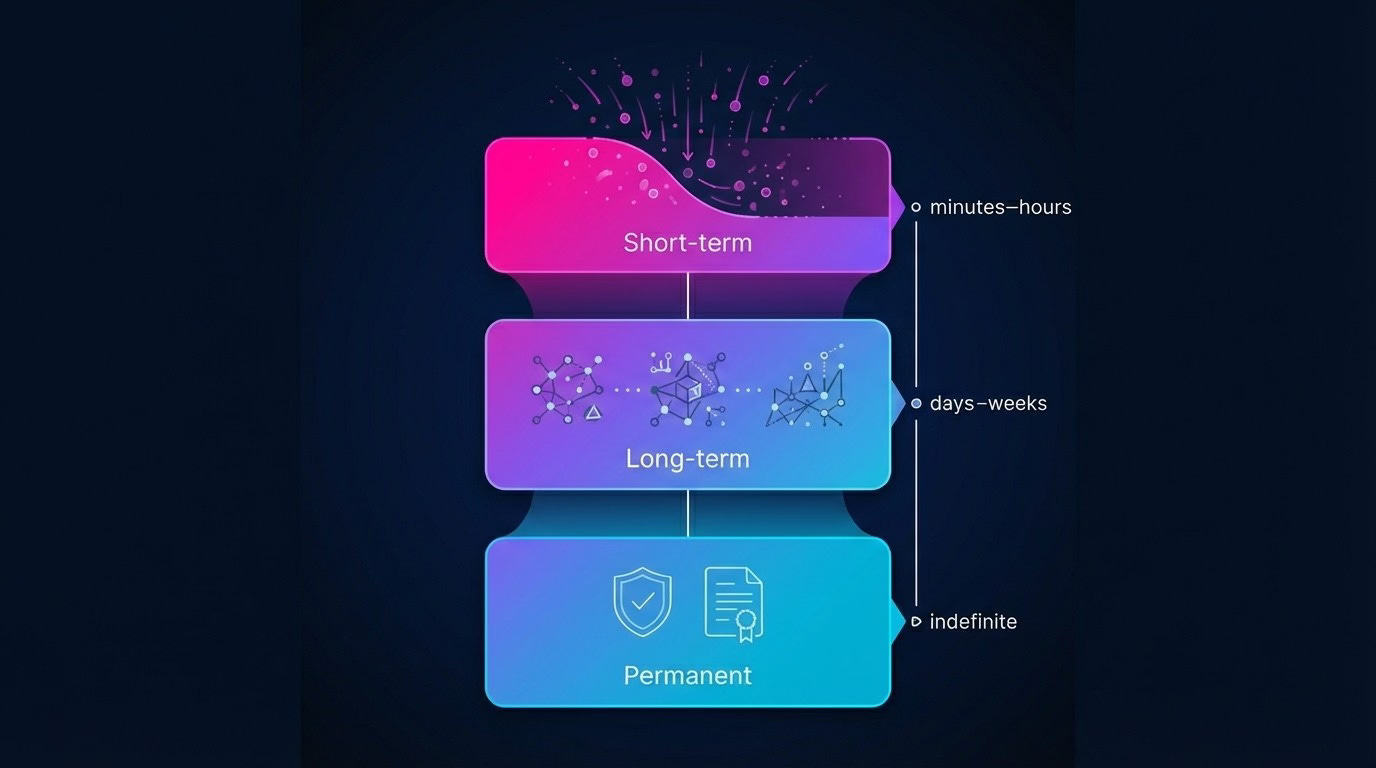
To see how these layers compose, trace a single event through the system.
14:32:07 A robot’s low-power proximity sensor detects something unexpected on the floor of aisle 7. This triggers the high-resolution camera. (Layer 1: cascaded wake-up)
14:32:08 The onboard SLM processes the camera frame, classifies it as a liquid spill with 94% confidence, and generates a structured observation: {type: “hazard”, subtype: “spill”, location: [7, 42.3], severity: “medium”, timestamp: 1732456328}. The model also decides this warrants immediate peer notification rather than waiting for the next gossip cycle. (Layer 2: local AI processing)
14:32:09 The robot signs the observation and pushes it to three nearby peers. Those peers validate the signature, incorporate the observation into their local state, and relay it further. Within 800ms, 47 of 52 active robots in the facility have received the alert. (Layer 3: gossip protocol)
14:32:10 Each robot updates its local CRDT replica: the OR-Set of active hazards gains a new entry, and the LWW-Map of aisle statuses updates aisle 7 to “caution”. Route-planning queries now automatically factor in the hazard. (Layer 4: shared memory)
14:32:15 A robot already en route through aisle 7 recalculates its path mid-transit and diverts to aisle 8. No central coordinator made this decision; the robot simply queried its local (now-updated) memory and acted.
14:47:00 A maintenance worker clears the spill and taps a confirmation on a handheld device. That device gossips a “hazard resolved” message, the OR-Set removes the entry, and normal routing resumes.
The entire cycle - detection to coordinated response - happened without a single cloud round-trip in the critical path.
Cross-Cutting Concerns: Operations and Governance
The four layers describe what the system does. But some of the hardest problems live in the operational layer: keeping it running safely over time.
Model Lifecycle
SLMs are versioned, signed, and rolled out gradually. Canary subsets of devices get new versions first; if metrics degrade, you roll back. Edge models are monitored for changes in input distribution and behavior - suspicious patterns (e.g., more near-miss safety incidents) trigger investigation and retraining.
Observability
When decisions are made locally by many agents, debugging from the outside is hard. You need structured logs and compact traces of what the agent believed and why it acted. You can’t ship every log line; you have to summarize, sample, and retrieve more detail only when needed. Correlating behavior across hundreds of devices requires consistent identifiers, synchronized clocks, and good tooling.
Security and Trust
Key questions that matter in production: How are device identities provisioned and rotated? How do you prevent Sybil attacks in a gossip network? What happens when a device is stolen or compromised? How do you respect privacy laws (GDPR, HIPAA, etc.) when sensors observe people?
The four-layer architecture doesn’t answer these by itself, but it gives you the hooks: cryptographic signatures and secure enclaves for identities, gossip and CRDTs instrumented with provenance and trust metadata, central governance services for revocation lists, policy updates, and audit.
Designing these operational flows is just as important as picking the right CRDT or consensus protocol.
Smarter Together
Here’s the encouraging part: most of the building blocks already exist. SLMs that fit on edge hardware are shipping. Efficient gossip protocols (SWIM, HyParView, etc.) are well-studied. CRDT libraries are battle-tested in databases and distributed systems. Consensus algorithms like RAFT are widely implemented and understood.
What matters isn’t any single technology. It’s the composition: deciding which decisions stay local vs. global, choosing where you can live with eventual consistency vs. where you pay for strong guarantees, and making the whole thing observable, governable, and safe as the number of agents scales.
Autonomous AI collectives are what you get when you treat edge devices as peers rather than dumb endpoints: devices that sense, reason, communicate, and remember - together.
The cloud isn’t going anywhere. It remains the place where you train and evaluate powerful models, aggregate telemetry and refine policies, and coordinate security, governance, and compliance. But increasingly, the edge is where intelligence reacts in real time and learns local patterns that would be invisible from a distance.
If you’re trying to move from ‘smart devices’ to real AI collectives, I’m happy to chat about architectures and trade-offs. What edge/collective problems are you wrestling with?
References
Demers, A. et al. (1987). Epidemic Algorithms for Replicated Database Maintenance. PODC ‘87. (https://dl.acm.org/doi/10.1145/41840.41841)
Shapiro, M. et al. (2011). Conflict-free Replicated Data Types. SSS 2011. (https://link.springer.com/chapter/10.1007/978-3-642-24550-3_29)
Shapiro, M. et al. (2011). A Comprehensive Study of Convergent and Commutative Replicated Data Types. INRIA RR-7506. (https://inria.hal.science/inria-00555588/document)
Almeida, P.S., Shoker, A., Baquero, C. (2018). Delta State Replicated Data Types. JPDC. (https://www.sciencedirect.com/science/article/pii/S0743731517302332)
Kleppmann, M. (2022). Making CRDTs Byzantine Fault Tolerant. PaPoC ‘22. (https://martin.kleppmann.com/papers/bft-crdt-papoc22.pdf)
Ongaro, D. & Ousterhout, J. (2014). In Search of an Understandable Consensus Algorithm. USENIX ATC ‘14. (https://raft.github.io/raft.pdf)
Das, A., Gupta, I., Motivala, A. (2002). SWIM: Scalable Weakly-consistent Infection-style Process Group Membership Protocol. DSN 2002. (https://ieeexplore.ieee.org/document/1028914)
Leitão, J., Pereira, J., Rodrigues, L. (2007). HyParView: A Membership Protocol for Reliable Gossip-Based Broadcast. DSN 2007. (https://ieeexplore.ieee.org/document/4272993)
Karp, R. et al. (2000). Randomized Rumor Spreading. FOCS 2000. (https://ieeexplore.ieee.org/document/892324)
Belcak, P. et al. (2025). Small Language Models are the Future of Agentic AI. arXiv:2506.02153. (https://arxiv.org/abs/2506.02153)
Xu, Z. et al. (2023). Federated Learning of Gboard Language Models with Differential Privacy. arXiv:2305.18465. (https://arxiv.org/abs/2305.18465)
Habiba, U. & Khan, M.A. (2025). Revisiting Gossip Protocols for Agentic Multi-Agent Systems. arXiv:2508.01531. (https://arxiv.org/abs/2508.01531)